


1、单选题:
Information analytics include:
选项:
A: Data organization
B: Data interpretation
C: Data visualization
D: All of above.
答案: 【 All of above.】
2、单选题:
Which one of the following categories does the age of a student (e.g., 19) belong to?
选项:
A: Nominal
B: Ordinal
C: Interval
D: Ratio
答案: 【 Interval】
3、单选题:
Which one of the following categories does the gender of a student (e.g., female) belong to?
选项:
A: Nominal
B: Ordinal
C: Interval
D: Ratio
答案: 【 Nominal】
4、单选题:
Which one of the following categories does the average score of a course (e.g., 85.2) belong to?
选项:
A: Nominal
B: Ordinal
C: Interval
D: Ratio
答案: 【 Ratio】
5、单选题:
Which one of the following categories does the ranking of a student’s score (e.g., 2) belong to?
选项:
A: Nominal
B: Ordinal
C: Interval
D: Ratio
答案: 【 Ordinal】
1、单选题:
What is the ultimate purpose of data analysis?
选项:
A: To build a model to perform simulation
B: To gain insights and help with decision making
C: To make a descriptive analysis and visualize the data
D: To build a model to perform simulation
答案: 【 To gain insights and help with decision making】
2、判断题:
When optimizing a model, we should always consider a trade-off between model interpretation and model accuracy.
选项:
A: 正确
B: 错误
答案: 【 正确】
3、填空题:
We will use Python, R and ____ in this class.
答案: 【 Stata】
4、填空题:
The stages of data analytics usually include feature selection, modeling and testing, model evaluation and .
答案: 【 optimization】
1、单选题:
Which of the following terminology is the same as reproducibility
选项:
A: Validity
B: Fair
C: Useful
D: Reliability
答案: 【 Reliability】
2、单选题:
Normalization with z-value can be used for
选项:
A: Normally distributed data
B: Symmetric but not normally distributed data
C: Uniformly distributed data
D: Exponentially distributed data
答案: 【 Normally distributed data】
3、填空题:
An indicator is a mathematical expression that can be applied to ________ data.
答案: 【 numerical】
1、单选题:
Which of the following indices can represent the degree of collaboration
选项:
A: 
B: 
C: 
D: 
答案: 【 】
2、判断题:
According to this figure, we can argue that collaboration enhances productivity.

选项:
A: 正确
B: 错误
答案: 【 错误】
1、单选题:
The first h articles ranked by the citation counts in descending order form the h-core, then h-tail is
选项:
A: all the other articles outside the h-core
B: the last h articles by the same ranking
C: randomly picked h articles
D: another h articles right following the h-core by the order
答案: 【 all the other articles outside the h-core】
2、单选题:
Read the following table and answer questions 2-4
The h index of this author is .
选项:
A: 4
B: 5
C: 6
D: 7
答案: 【 5】
3、单选题:
The h-core consists publication
选项:
A: A, B, C
B: A, B, C, D
C: A, B, C, D, E
D: A, B, C, D, E, F
答案: 【 A, B, C, D, E】
4、单选题:
The extended h-core including publications
选项:
A: A, B, C
B: A, B, C, D
C: A, B, C, D, E
D: A, B, C, D, E, F
答案: 【 A, B, C, D, E, F】
1、单选题:
Which of the following characteristics of the h-index is not correct
选项:
A: Simple
B: Relatively stable
C: Independent of productivity
D: Time-dependent
答案: 【 Independent of productivity】
2、单选题:
Which of the following has no chances to affect the value of the h-index?
选项:
A: Increasing the number of publications alone
B: Increasing the number of co-authors
C: Calculation errors
D: Increasing the number of citations
答案: 【 Increasing the number of co-authors】
3、判断题:
Does the h-index measure how GOOD a scientist is?
选项:
A: 正确
B: 错误
答案: 【 错误】
4、填空题:
One potential flaw of the h-index is that publications and citations are not _____ on each other.
答案: 【 independent】
1、单选题:
Choose the mathematical formula for density indicator in a directed network
选项:
A: 
B: 
C: 
D: 
答案: 【 】
2、单选题:
The closeness centrality can measure the _______ of a network.
选项:
A: activeness
B: efficiency
C: control over the flow
D: density
答案: 【 efficiency】
3、填空题:
The betweenness centrality is the number of times a node needs a given node to reach another node, which means it is the number of paths that pass through a given node.
答案: 【 shortest】
1、单选题:
Which of the following concepts is not relevent to the diversity indicators
选项:
A: Variety
B: Balance
C: Modularity
D: Disparity
答案: 【 Modularity】
2、单选题:
Which of the followings can lead to a larger diversity
选项:
A: higher disparity
B: lower disparity
C: less balanced distribution
D: less variety
答案: 【 higher disparity】
3、判断题:
Balance describes the number of distinctive categories.
选项:
A: 正确
B: 错误
答案: 【 错误】
4、判断题:
Variety is a function of fractions summing up to one.
选项:
A: 正确
B: 错误
答案: 【 错误】
1、单选题:
Which of the following statement of classical analysis and EDA is not true:
选项:
A: In classical analysis, we build models before analysis
B: In EDA, we estimate the model directly after preparing data
C: In classical analysis, we spend most of our time estimating and testing hypothetical models
D: In EDA, we focus more on the true distribution of data and emphasize the visualization of data
答案: 【 In EDA, we estimate the model directly after preparing data】
2、单选题:
Which one of the following does not belong to the descriptive statistics of one quantitative variable:
选项:
A: Maximum
B: Average
C: 40 percentiles
D: Distribution
答案: 【 Distribution】
3、单选题:
If the following figure is the PDF plot, then _ is the CDF plot.

选项:
A: 
B: 
C:
D:
答案: 【 】
4、填空题:
The Matthew effect is examplified in this lecture as: a limited number of papers have a __ number of citations:
答案: 【 large##%_YZPRLFH_%##big##%_YZPRLFH_%##great】
1、单选题:
Which of the following cannot be used for bivariate data analysis:
选项:
A: Scatter plot
B: Pearson’s correlation coefficient
C: One-dimensional distribution
D: Regression analysis
答案: 【 One-dimensional distribution】
2、单选题:
In situation _, we will use Pearson’s correlation coefficient.
选项:
A: Continuous, normally distributed, linear data
B: Continuous, normally distributed data
C: Two sequential data
D: Continuous, uniformly distributed, linear data
答案: 【 Continuous, normally distributed, linear data】
3、单选题:
In the example about confidence interval in this lecture, why do we draw samples for 1000 times?
选项:
A: Decrease the negative effect from unusual data points
B: Avoid Matthew effect
C: Increase sample size to facilitate aggregate variable
D: Provide enough data for regression analysis
答案: 【 Decrease the negative effect from unusual data points】
4、单选题:
Which of the following is not a method used for multivariate data analysis:
选项:
A: Bubble plot
B: Pairwise analysis
C: Single scatter plot
D: Regression analysis
答案: 【 Single scatter plot】
1、单选题:
Which of the following value shows a positive correlation:
选项:
A: 1.0
B: 1.5
C: -1.0
D: -1.5
答案: 【 1.0】
2、单选题:
We usually use _ to test Pearson correlation coefficient.
选项:
A: z-test
B: t-test
C: Normalization
D: Chi-square test
答案: 【 t-test】
3、单选题:
We usually use __ to test Spearman rank order correlation coefficient.
选项:
A: z-test
B: t-test
C: Normalization
D: Chi-square test
答案: 【 z-test】
4、单选题:
Which of the following statements of Spearman rank order correlation coefficient and Kendall rank correlation coefficient is true?
选项:
A: We change original data to rank pair of data in Spearman rank order correlation coefficient to eliminate the influence of outliers.
B: For categorical variables, we need to use Spearman rank order correlation coefficient.
C: For two sequential measurement variables, we need to use Kendall rank correlation coefficient.
D: For continuous, normally distributed, linear variables, we need to use Spearman rank order correlation coefficient.
答案: 【 We change original data to rank pair of data in Spearman rank order correlation coefficient to eliminate the influence of outliers.】
1、单选题:
Which of the following statement about regression analysis is not true?
选项:
A: Regression method analyzes the quantitative causal relationship between the independent variable and the dependent variable.
B: Regression analysis can be divided to quantitative variable regression and classified variable regression.
C: Regression analysis can be classified depending on the number of variables.
D: Regression analysis is omnipotent.
答案: 【 Regression analysis is omnipotent. 】
2、单选题:
In the following equation 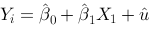 ,
,  is __.
is __.
选项:
A: residual
B: fitted value
C: real independent variable
D: estimated parameter
答案: 【 residual】
3、单选题:
According to the rule of OLS, the __ needs to be the smallest.
选项:
A: total sum of squares
B: residual sum of squares
C: explained sum of squares
D: regression
答案: 【 residual sum of squares】
4、单选题:
Which of the following statement for goodness of fit test for OLS is not true.
选项:
A: Goodness of fit test is used to describe the volatility of Yi relative to its fitted value.
B: TSS = ESS + RSS
C: 
D: The larger 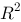 is, the better regression line fits.
is, the better regression line fits.
答案: 【 Goodness of fit test is used to describe the volatility of Yi relative to its fitted value.】
1、单选题:
Based on what you have learned about types of regression, which of the following statement is true?
选项:
A: PLS regression can be used for several quantitative dependent variables.
B: Logistic regression can be used when the independent variable and the dependent variable are not linear.
C: Polynomial regression can be used when the dependent variables are categorized.
D: Multiple linear regression can be used for several quantitative dependent variables.
答案: 【 PLS regression can be used for several quantitative dependent variables.】
2、单选题:
This is a matrix multiplication for multiple linear regression, 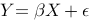 ,if n is the number of independent variables and
,if n is the number of independent variables and 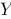 is an n×1 column vector, p is the number of observations, then which of the following statement is true?
is an n×1 column vector, p is the number of observations, then which of the following statement is true?
选项:
A: 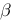 is a p×1 vector of parameters.
is a p×1 vector of parameters.
B: 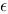 is an (n+1)×1 vector of random errors.
is an (n+1)×1 vector of random errors.
C: 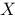 is an n×(p+1) matrix.
is an n×(p+1) matrix.
D: 
答案: 【 is an n×(p+1) matrix. 】
3、单选题:
Which of the following describes the estimated parameter of multiple linear regression?
选项:
A: 
B: 
C: 
D:


备案号:冀ICP备20010840号 2020-2099辉辉网络科技 All Rights Reserved


{kind=link}